9. Some Probability Distributions#
This lecture is a supplement to this lecture on statistics with matrices.
It describes some popular distributions and uses Python to sample from them.
It also describes a way to sample from an arbitrary probability distribution that you make up by transforming a sample from a uniform probability distribution.
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install prettytable
As usual, we’ll start with some imports
import numpy as np
import matplotlib.pyplot as plt
import prettytable as pt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib_inline.backend_inline import set_matplotlib_formats
set_matplotlib_formats('retina')
9.1. Some Discrete Probability Distributions#
Let’s write some Python code to compute means and variances of some univariate random variables.
We’ll use our code to
compute population means and variances from the probability distribution
generate a sample of
compare population and sample means and variances
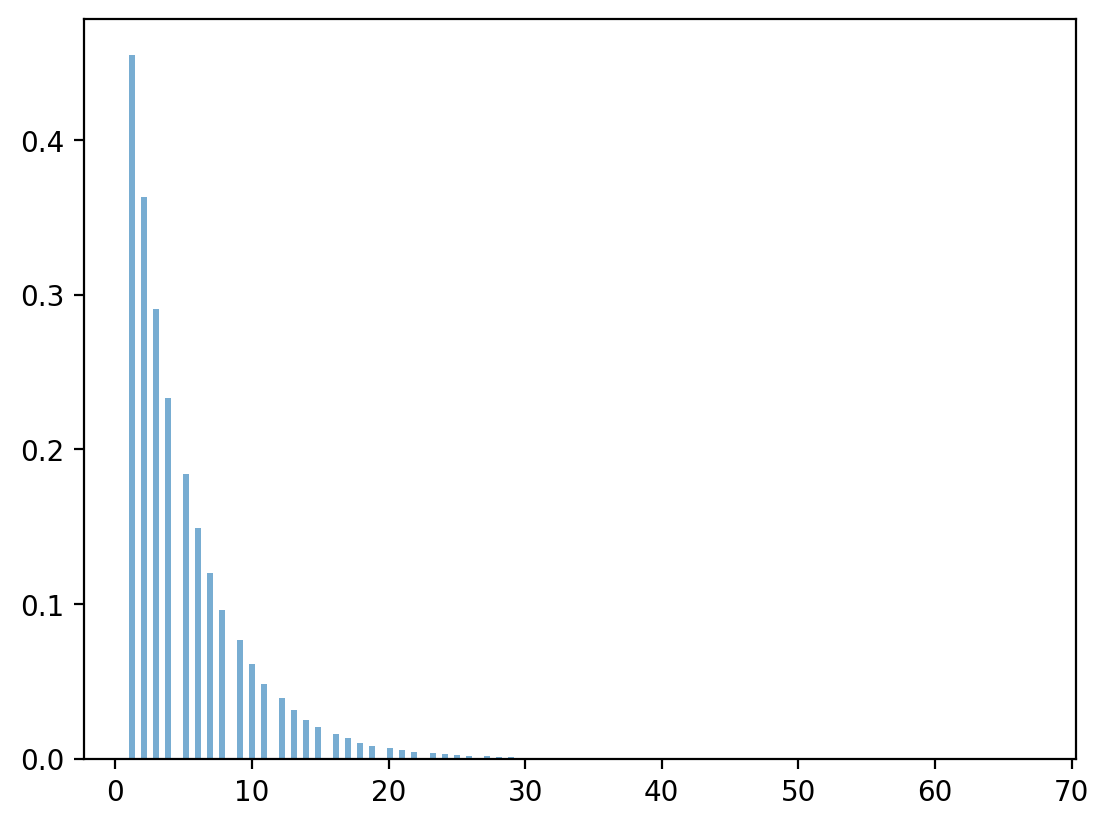
9.2. Geometric distribution#
A discrete geometric distribution has probability mass function
where
The mean and variance of this one-parameter probability distribution are
Let’s use Python draw observations from the distribution and compare the sample mean and variance with the theoretical results.
# specify parameters
p, n = 0.3, 1_000_000
# draw observations from the distribution
x = np.random.geometric(p, n)
# compute sample mean and variance
μ_hat = np.mean(x)
σ2_hat = np.var(x)
print("The sample mean is: ", μ_hat, "\nThe sample variance is: ", σ2_hat)
# compare with theoretical results
print("\nThe population mean is: ", 1/p)
print("The population variance is: ", (1-p)/(p**2))
The sample mean is: 3.334742
The sample variance is: 7.763557793435998
The population mean is: 3.3333333333333335
The population variance is: 7.777777777777778
9.3. Pascal (negative binomial) distribution#
Consider a sequence of independent Bernoulli trials.
Let
Let
Its distribution is
Here, we choose from among
We compute the mean and variance to be
# specify parameters
r, p, n = 10, 0.3, 1_000_000
# draw observations from the distribution
x = np.random.negative_binomial(r, p, n)
# compute sample mean and variance
μ_hat = np.mean(x)
σ2_hat = np.var(x)
print("The sample mean is: ", μ_hat, "\nThe sample variance is: ", σ2_hat)
print("\nThe population mean is: ", r*(1-p)/p)
print("The population variance is: ", r*(1-p)/p**2)
The sample mean is: 23.325444
The sample variance is: 77.83040620286394
The population mean is: 23.333333333333336
The population variance is: 77.77777777777779
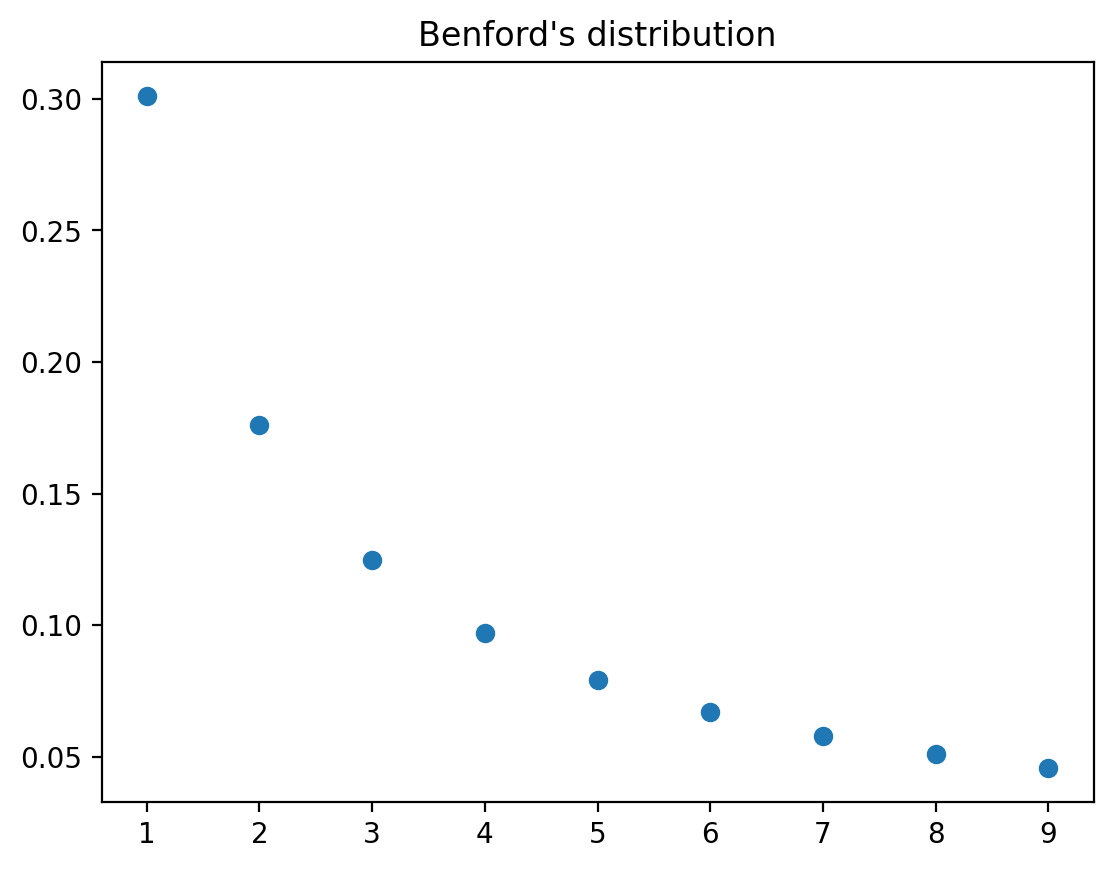
9.4. Newcomb–Benford distribution#
The Newcomb–Benford law fits many data sets, e.g., reports of incomes to tax authorities, in which the leading digit is more likely to be small than large.
See https://en.wikipedia.org/wiki/Benford’s_law
A Benford probability distribution is
where
This is a well defined discrete distribution since we can verify that probabilities are nonnegative and sum to
The mean and variance of a Benford distribution are
We verify the above and compute the mean and variance using numpy.
Benford_pmf = np.array([np.log10(1+1/d) for d in range(1,10)])
k = np.arange(1, 10)
# mean
mean = k @ Benford_pmf
# variance
var = ((k - mean) ** 2) @ Benford_pmf
# verify sum to 1
print(np.sum(Benford_pmf))
print(mean)
print(var)
0.9999999999999999
3.440236967123206
6.056512631375666
# plot distribution
plt.plot(range(1,10), Benford_pmf, 'o')
plt.title('Benford\'s distribution')
plt.show()
Now let’s turn to some continuous random variables.
9.5. Univariate Gaussian distribution#
We write
to indicate the probability distribution
In the below example, we set
# specify parameters
μ, σ = 0, 0.1
# specify number of draws
n = 1_000_000
# draw observations from the distribution
x = np.random.normal(μ, σ, n)
# compute sample mean and variance
μ_hat = np.mean(x)
σ_hat = np.std(x)
print("The sample mean is: ", μ_hat)
print("The sample standard deviation is: ", σ_hat)
The sample mean is: -2.8548065661503377e-05
The sample standard deviation is: 0.09990243468371045
# compare
print(μ-μ_hat < 1e-3)
print(σ-σ_hat < 1e-3)
True
True
9.6. Uniform Distribution#
The population mean and variance are
# specify parameters
a, b = 10, 20
# specify number of draws
n = 1_000_000
# draw observations from the distribution
x = a + (b-a)*np.random.rand(n)
# compute sample mean and variance
μ_hat = np.mean(x)
σ2_hat = np.var(x)
print("The sample mean is: ", μ_hat, "\nThe sample variance is: ", σ2_hat)
print("\nThe population mean is: ", (a+b)/2)
print("The population variance is: ", (b-a)**2/12)
The sample mean is: 15.00250459918252
The sample variance is: 8.342970489200585
The population mean is: 15.0
The population variance is: 8.333333333333334
9.7. A Mixed Discrete-Continuous Distribution#
We’ll motivate this example with a little story.
Suppose that to apply for a job you take an interview and either pass or fail it.
You have
We can describe your daily salary as a discrete-continuous variable with the following probabilities:
Let’s start by generating a random sample and computing sample moments.
x = np.random.rand(1_000_000)
# x[x > 0.95] = 100*x[x > 0.95]+300
x[x > 0.95] = 100*np.random.rand(len(x[x > 0.95]))+300
x[x <= 0.95] = 0
μ_hat = np.mean(x)
σ2_hat = np.var(x)
print("The sample mean is: ", μ_hat, "\nThe sample variance is: ", σ2_hat)
The sample mean is: 17.536613589301137
The sample variance is: 5874.314525073605
The analytical mean and variance can be computed:
mean = 0.0005*0.5*(400**2 - 300**2)
var = 0.95*17.5**2+0.0005/3*((400-17.5)**3-(300-17.5)**3)
print("mean: ", mean)
print("variance: ", var)
mean: 17.5
variance: 5860.416666666666
9.8. Drawing a Random Number from a Particular Distribution#
Suppose we have at our disposal a pseudo random number that draws a uniform random variable, i.e., one with probability distribution
How can we transform
The key tool is the inverse of a cumulative distribution function (CDF).
Observe that the CDF of a distribution is monotone and non-decreasing, taking values between
We can draw a sample of a random variable
draw a random variable
pass the sample value of
Thus, knowing the “inverse” CDF of a distribution is enough to simulate from this distribution.
Note
The “inverse” CDF needs to exist for this method to work.
The inverse CDF is
Here we use infimum because a CDF is a non-decreasing and right-continuous function.
Thus, suppose that
We want to sample a random variable
It turns out that if we use draw uniform random numbers
then
We’ll verify this in the special case in which
Note that
where the last equality occurs because
Let’s use numpy to compute some examples.
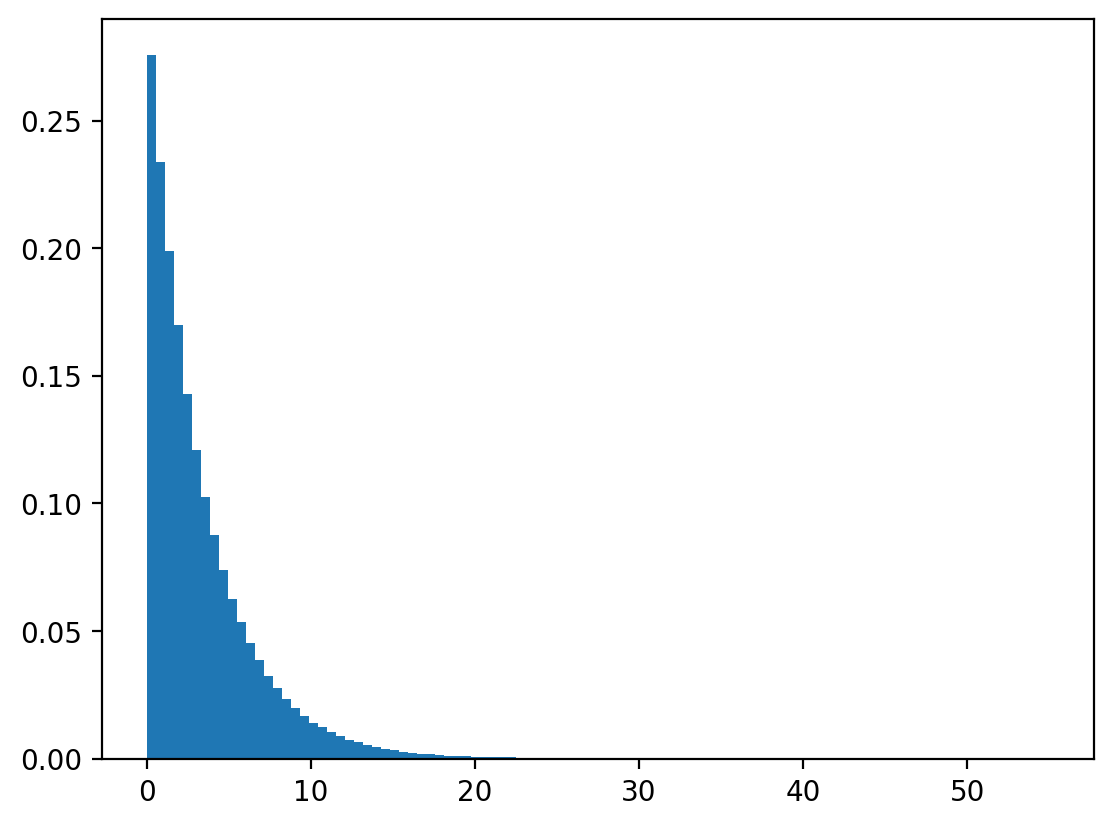
Example: A continuous geometric (exponential) distribution
Let
Its density function is
Its CDF is
Let
The distribution
Let’s draw
We’ll check whether
Let’s check with numpy.
n, λ = 1_000_000, 0.3
# draw uniform numbers
u = np.random.rand(n)
# transform
x = -np.log(1-u)/λ
# draw geometric distributions
x_g = np.random.exponential(1 / λ, n)
# plot and compare
plt.hist(x, bins=100, density=True)
plt.show()
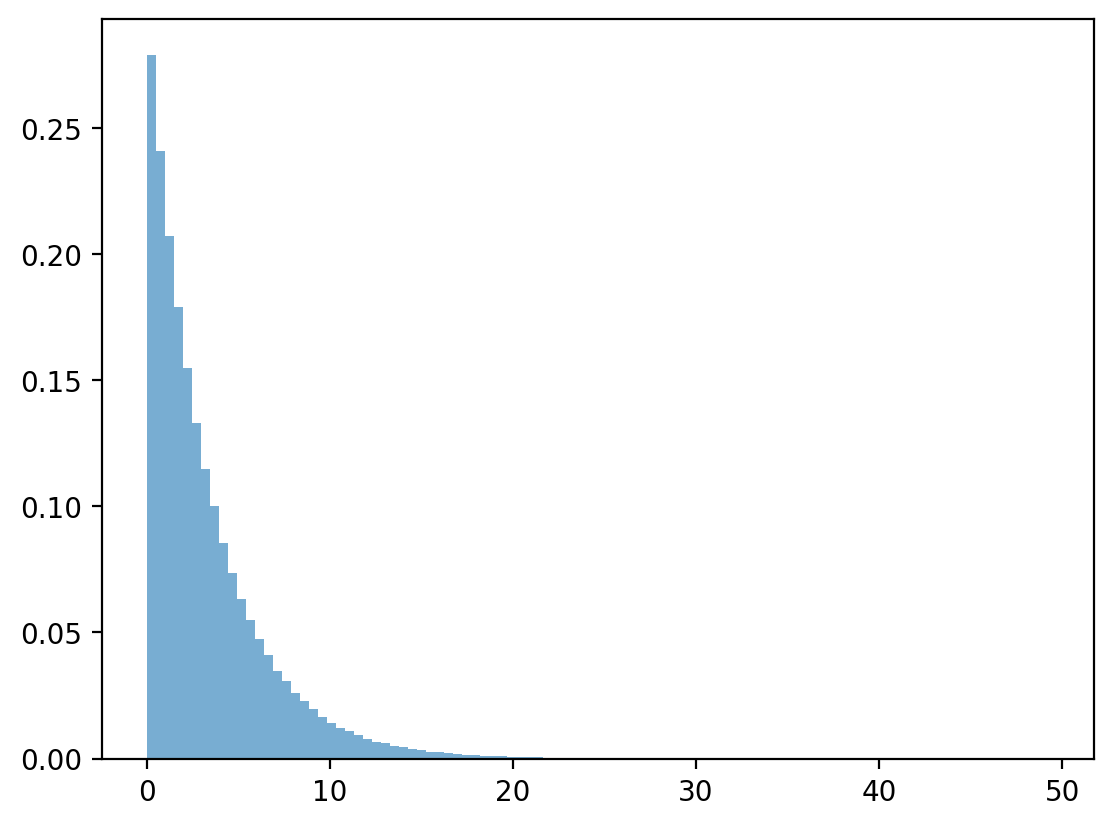
plt.hist(x_g, bins=100, density=True, alpha=0.6)
plt.show()
Geometric distribution
Let
Its CDF is given by
Again, let
Let’s deduce the distribution of
However,
So let
where
Thus
We can verify that numpy program.
Note
The exponential distribution is the continuous analog of geometric distribution.
n, λ = 1_000_000, 0.8
# draw uniform numbers
u = np.random.rand(n)
# transform
x = np.ceil(np.log(1-u)/np.log(λ) - 1)
# draw geometric distributions
x_g = np.random.geometric(1-λ, n)
# plot and compare
plt.hist(x, bins=150, density=True)
plt.show()
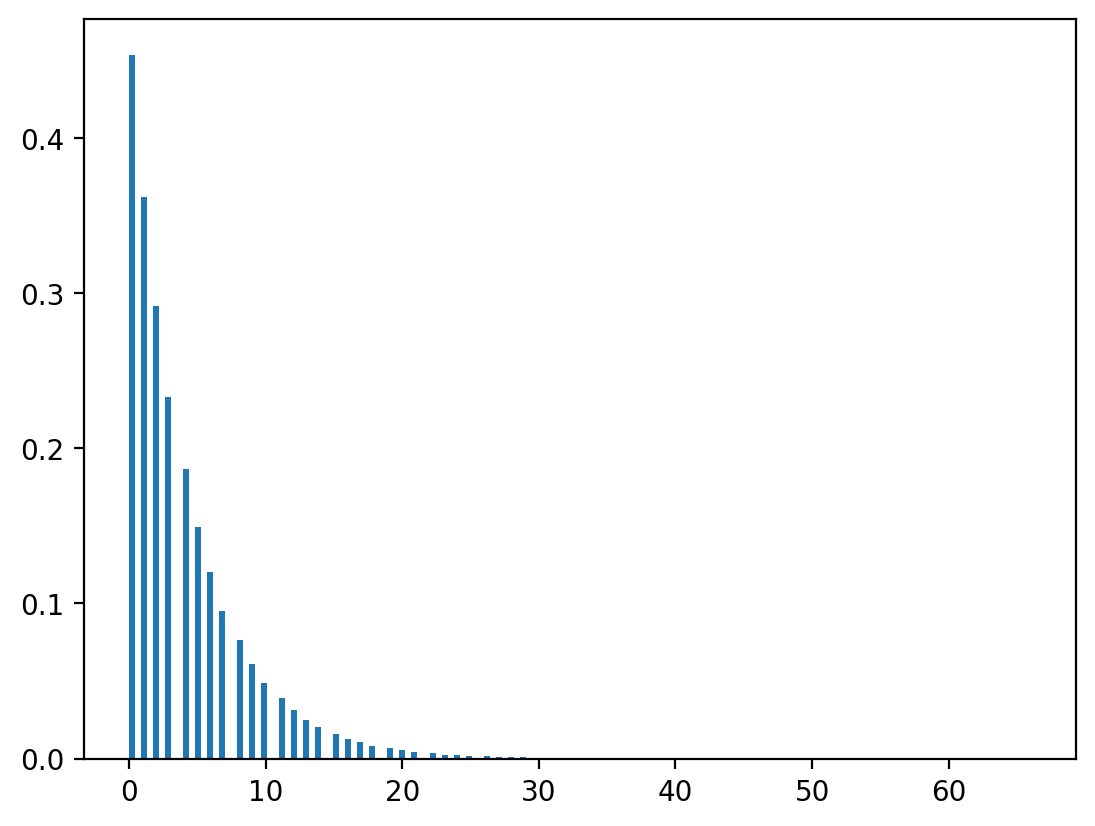
np.random.geometric(1-λ, n).max()
np.int64(74)
np.log(0.4)/np.log(0.3)
np.float64(0.7610560044063083)
plt.hist(x_g, bins=150, density=True, alpha=0.6)
plt.show()